
BDPS: An Efficient Spark-Based Big Data Processing Scheme for Cloud Fog-IoT Orchestration

 , , , ,
, , , ,  and
and
Abstract
:1. Introduction
- We present an efficient Spark-RDD-in-memory-based scheme to mitigate against existing challenges in a scheduled priority batch processing data distribution framework.
- We implement the delay efficient high-speed data processing algorithmic scheme for a hierarchical tree-based overlay mesh architecture in the cloud–fog and IoT ecosystem.
- We conduct an overall performance analysis of our scheme with shortest path algorithms, such as BF, FW and AH, with efficient delay time analysis (e.g., system run-time tolerance or service load).
2. Background Study with Related Work
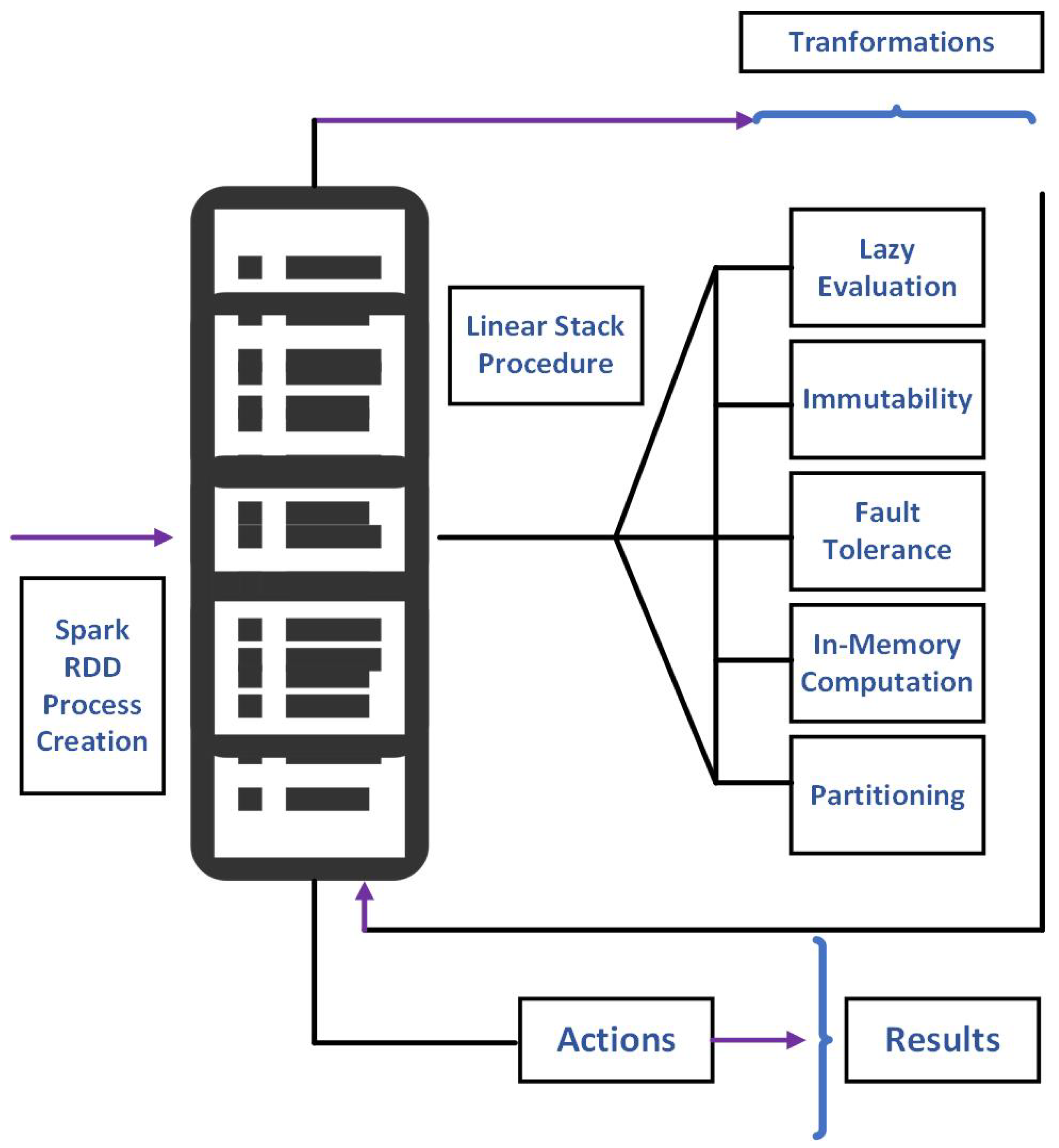
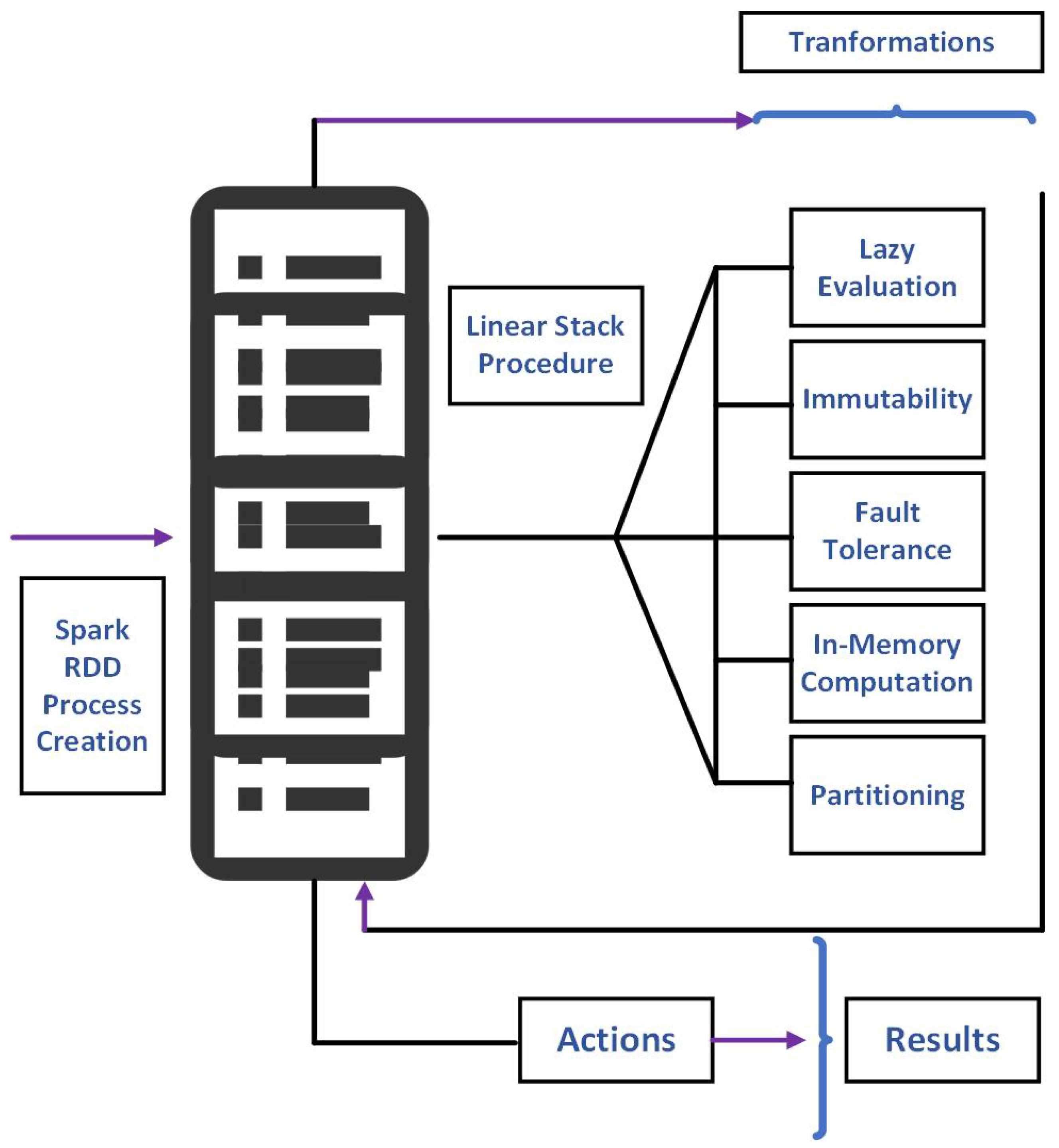
2.1. Spark-RDD
2.2. SDN
2.3. Fog-IoT
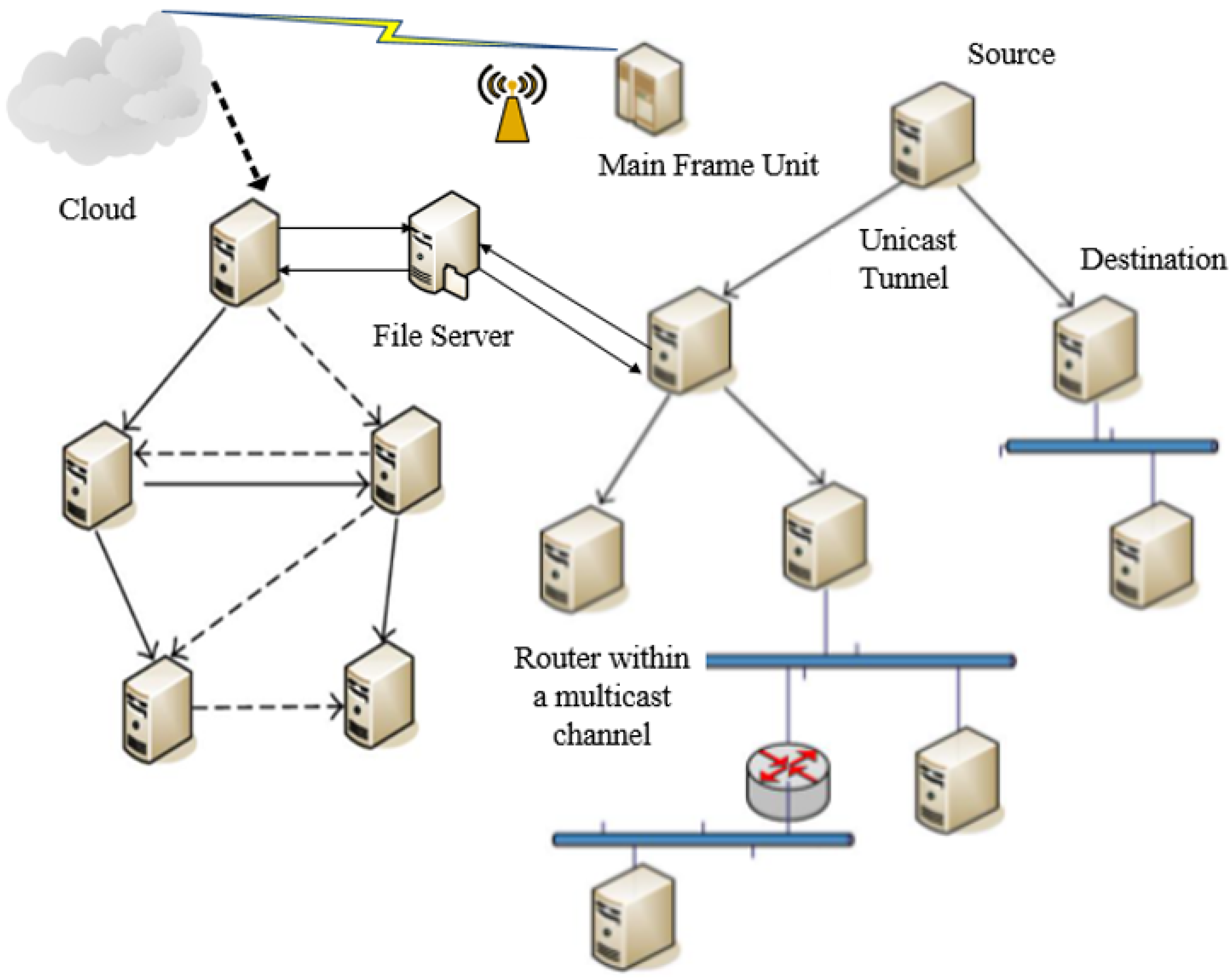
2.4. Overlay Tree Architecture
3. Related Works
4. System Model and Methodology
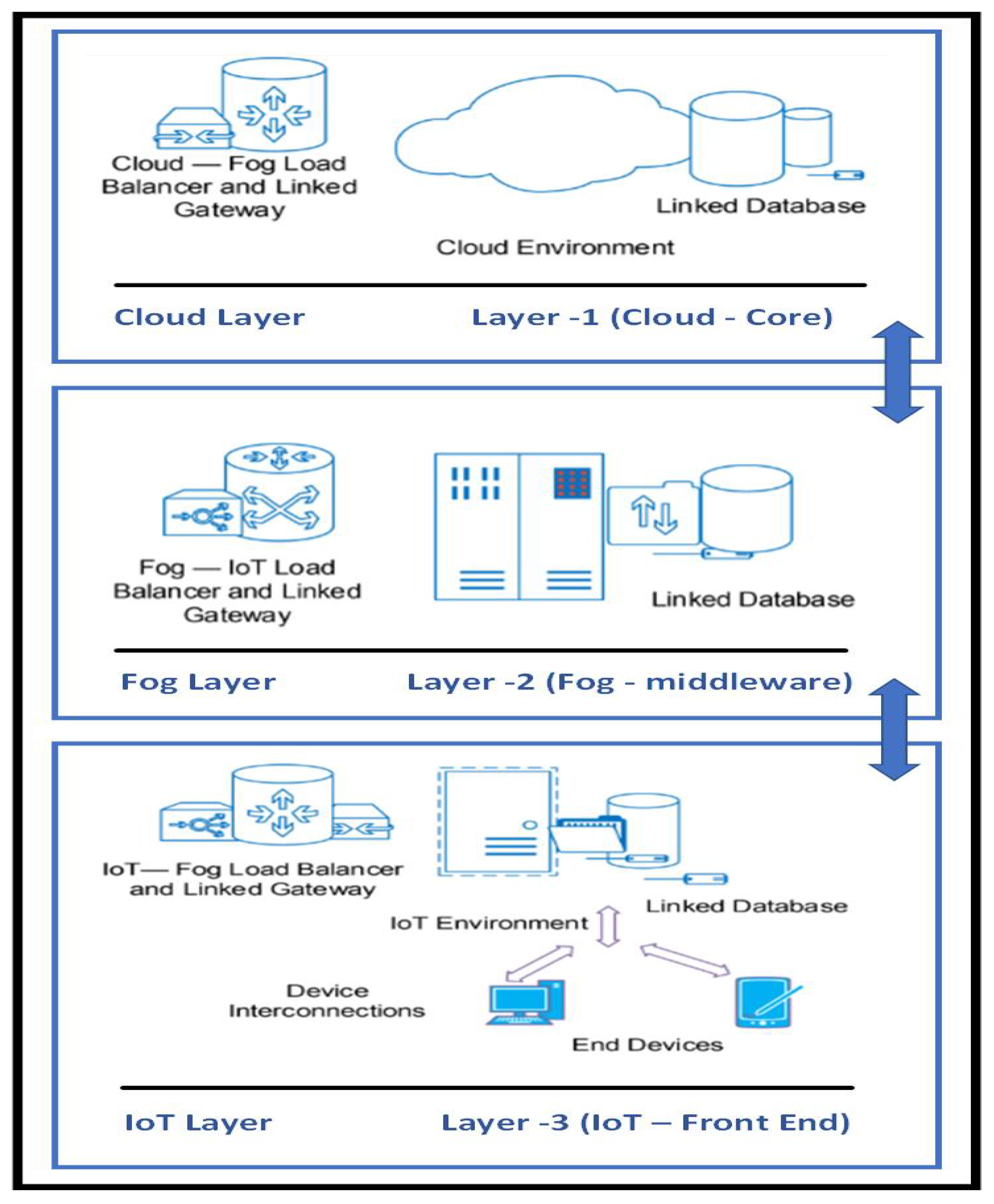
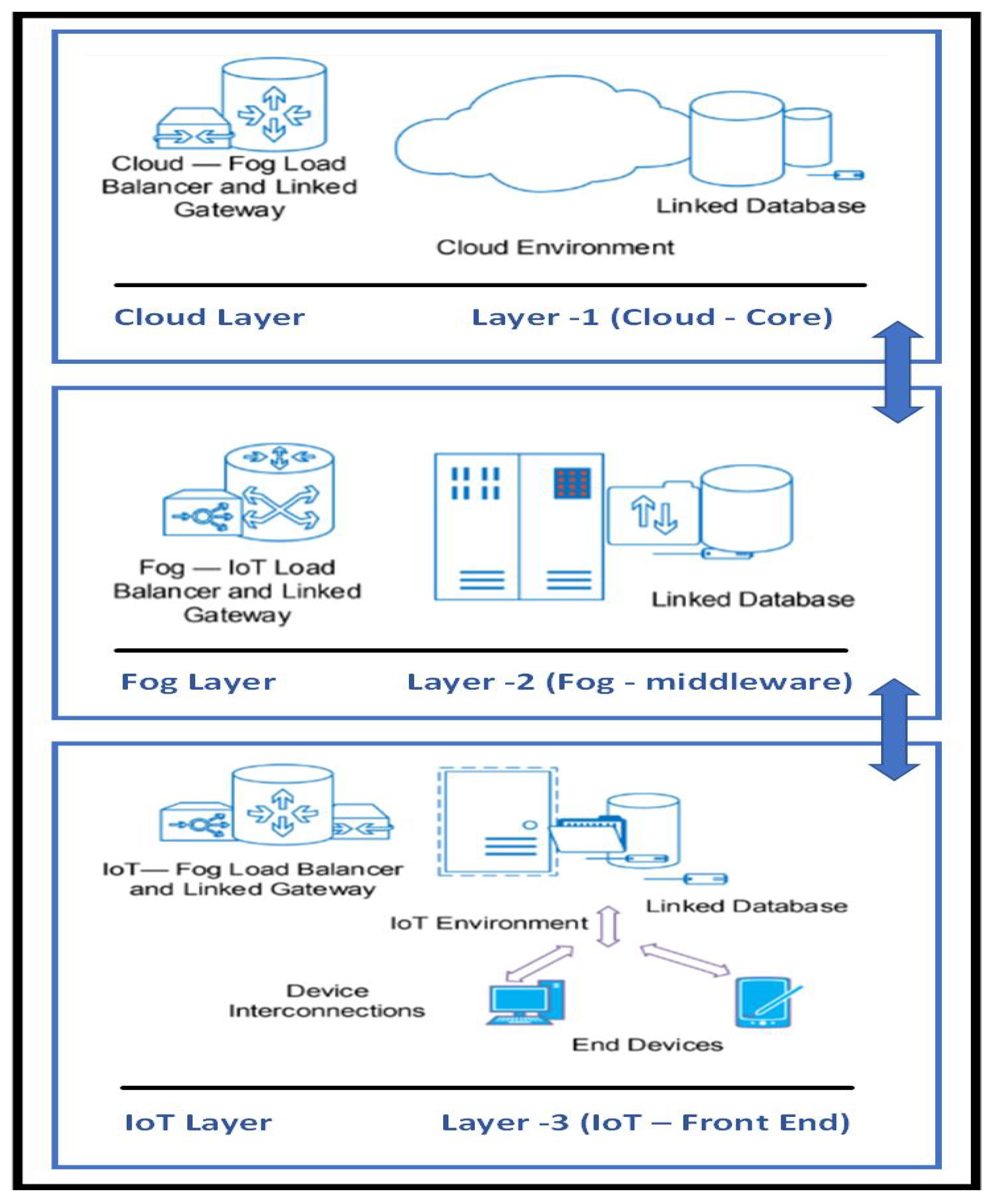
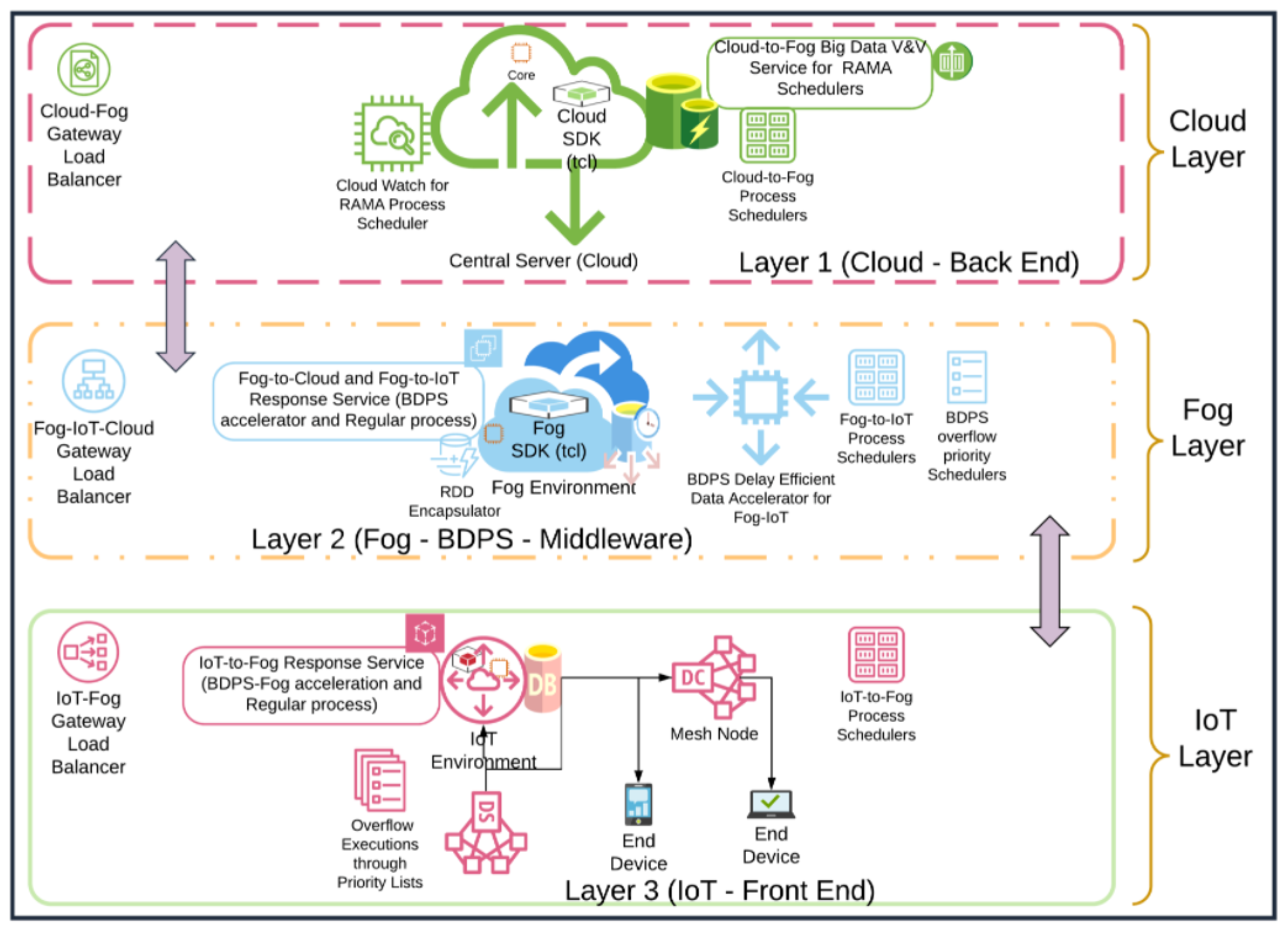
4.1. BDPS Data Processing in Cloud, Fog and IoT Network Layer
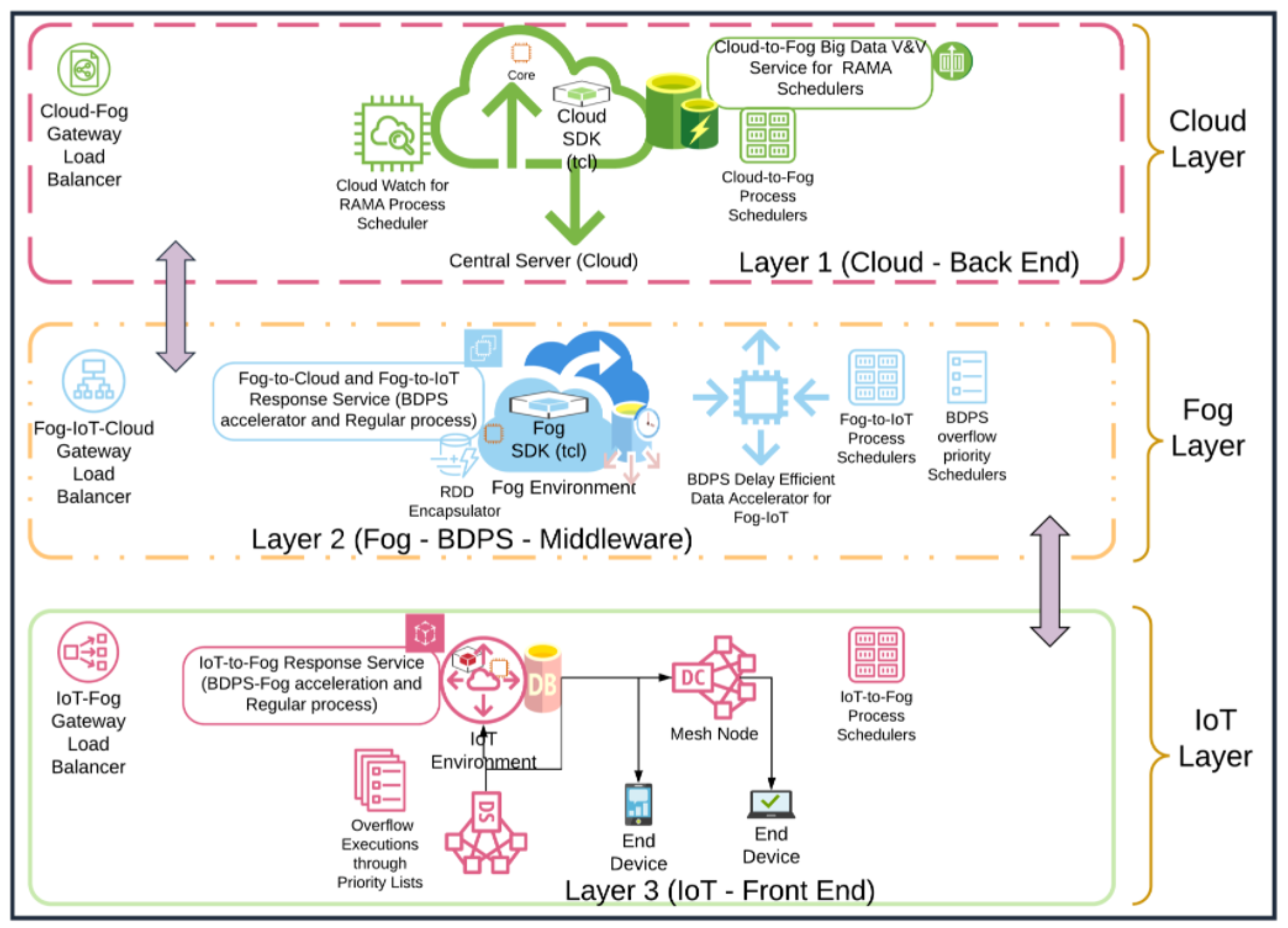
4.2. Components of the Fog-IoT Hierarchical Overlay Network and BDPS Architecture
| Algorithm 1: BDPS—delay efficient scheme for rapid data delivery (cloud, fog to IoT end)—Part 1 |
| Input: Overflow of queuing data processes at the network ends based on priority schedulers |
| Output: in-memory map-reduction-based functional RDD-RAMA data accelerators |
| /* = A Boolean value defines data Overflow of processes or Not, denoted as */ |
| /* = Priority-based threaded packet counter, denoted as */ |
| /* = Particular feed-forwarding scheduled packet for data into both , denoted as and */ |
| /*, denoted as */ |
| /*, denoted as */ |
| /*, denoted as */ |
| /*, denoted as */ |
| foreach in do |
 |
| Algorithm 2: BDPS—delay efficient scheme for rapid data delivery (cloud, fog to IoT end)—Part 2 |
| Input: Overflow of queuing data processes at the network ends based on priority schedulers |
| Output: in-memory map-reduction-based functional RDD-RAMA data accelerators |
| /* = A Boolean value defines data Overflow of processes or Not, denoted as */ |
| /* = Priority based threaded packet counter, denoted as */ |
| /* = Particular feed-forwarding scheduled packet for data into both , denoted as and */ |
| /*, denoted as */ |
| /*, denoted as */ |
| /*, denoted as */ |
| /*, denoted as */ |
| ifthen |
 |
5. Experimental Research and Analysis
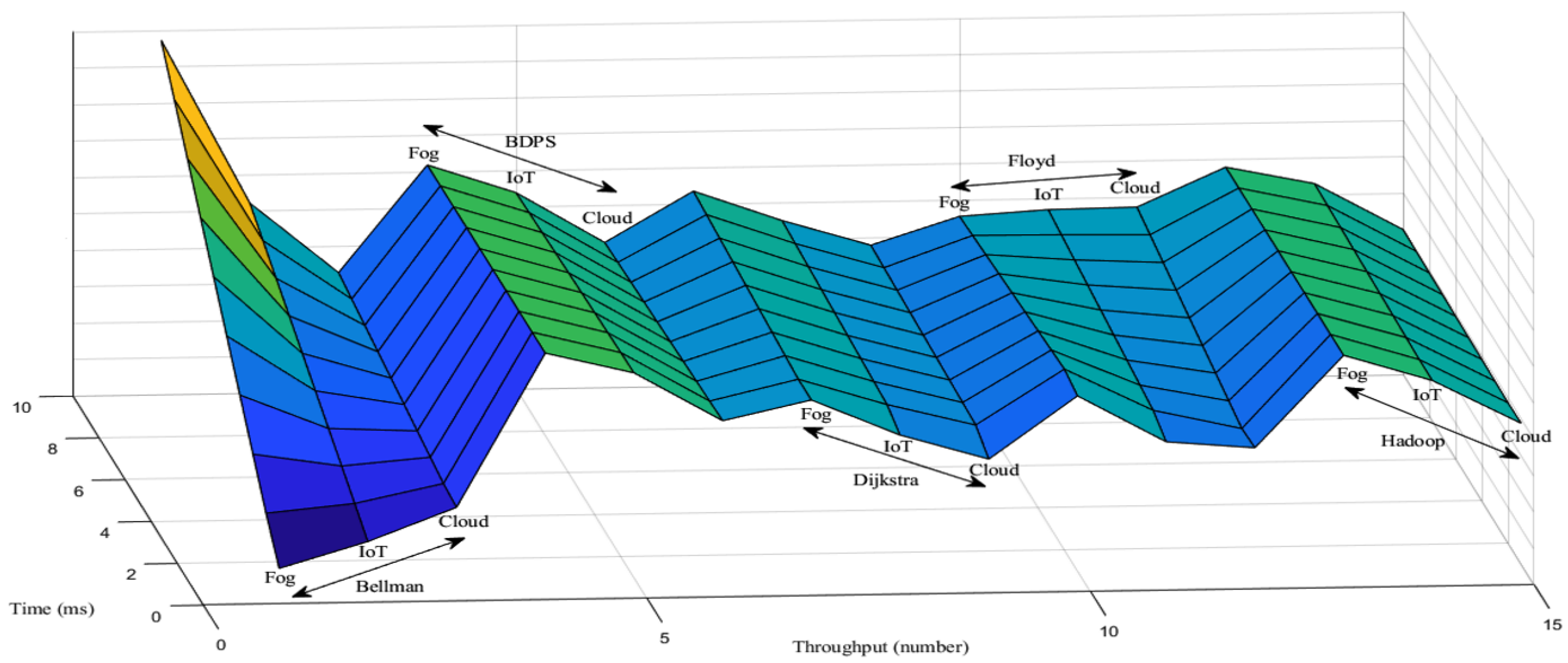
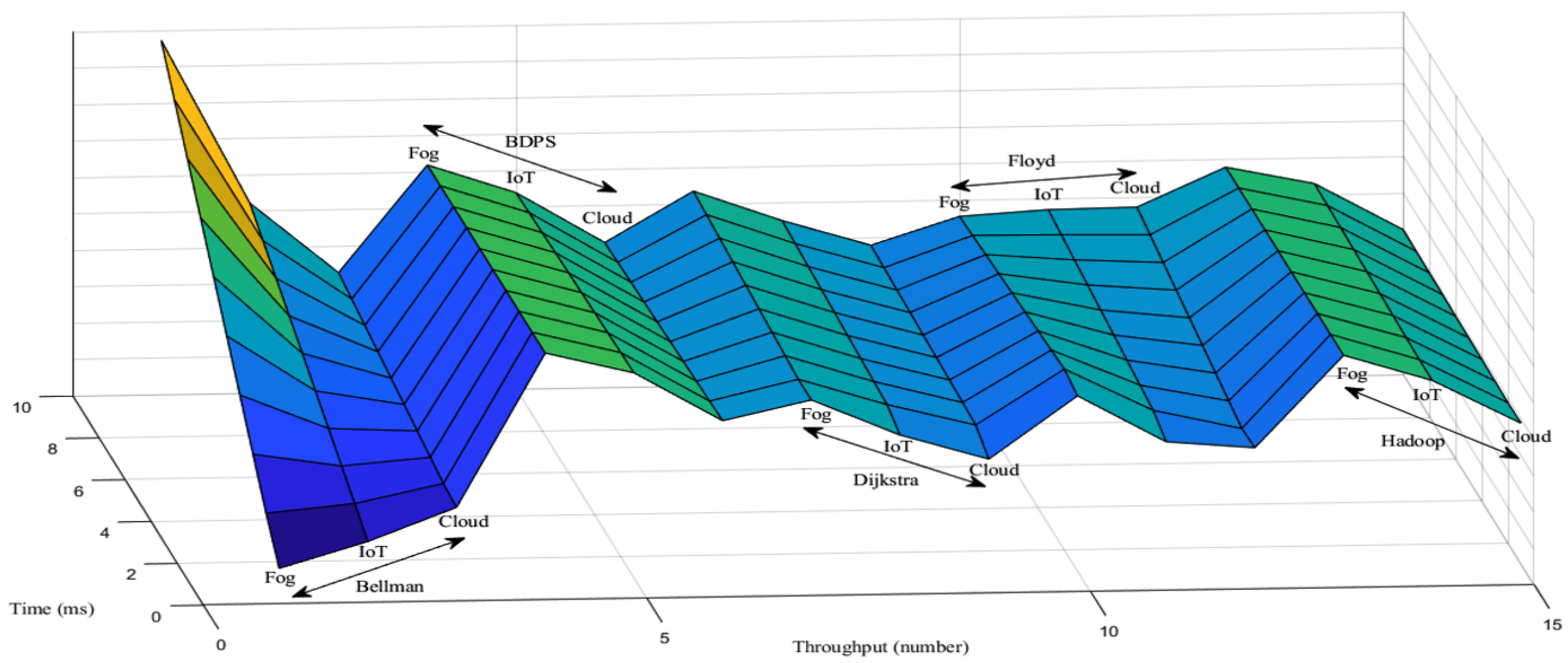
5.1. Throughput Generation Scenario over the FW, AH, BF, DA and BDPS Algorithm in Cloud, Fog, IoT Orchestration
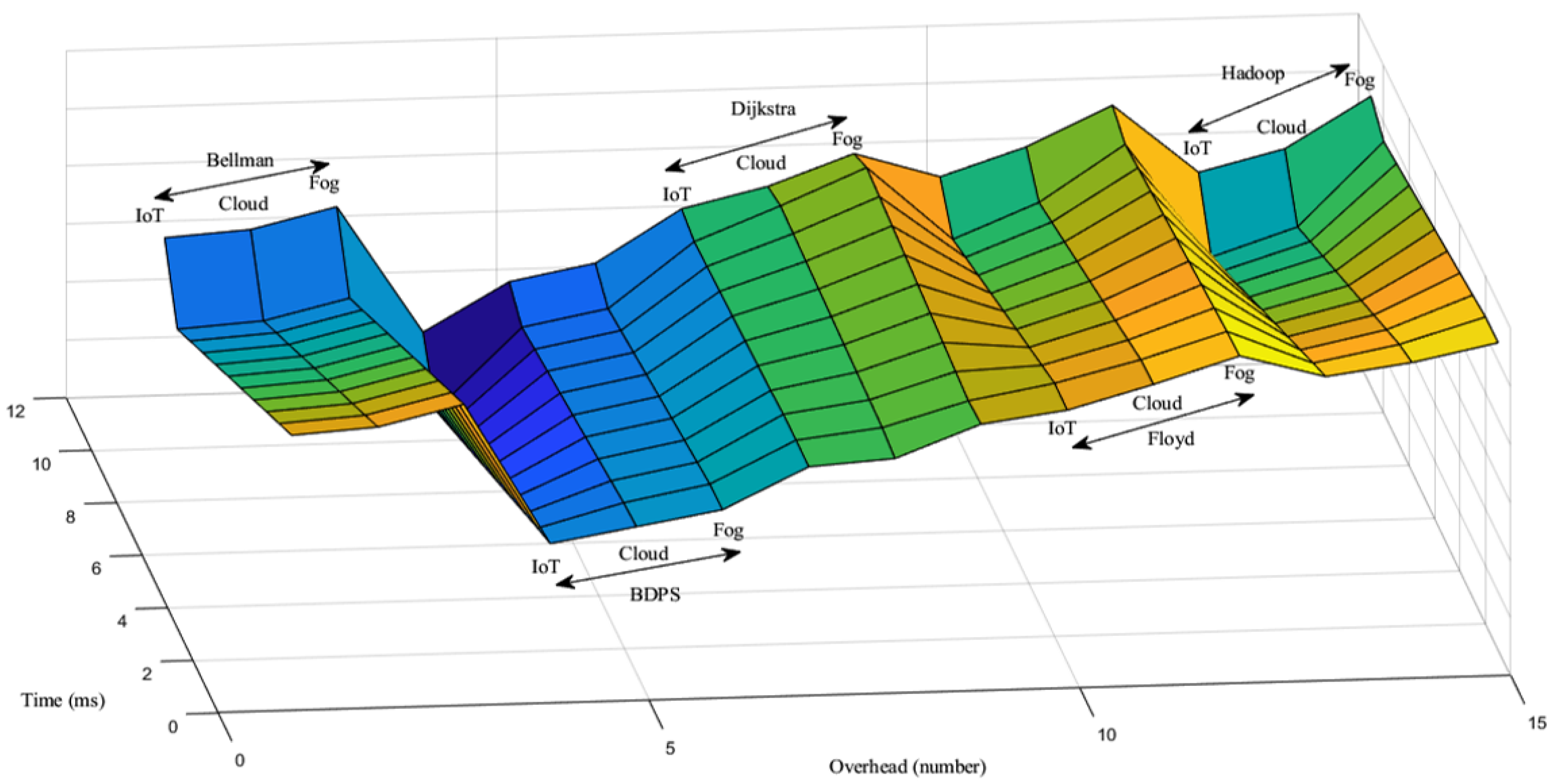
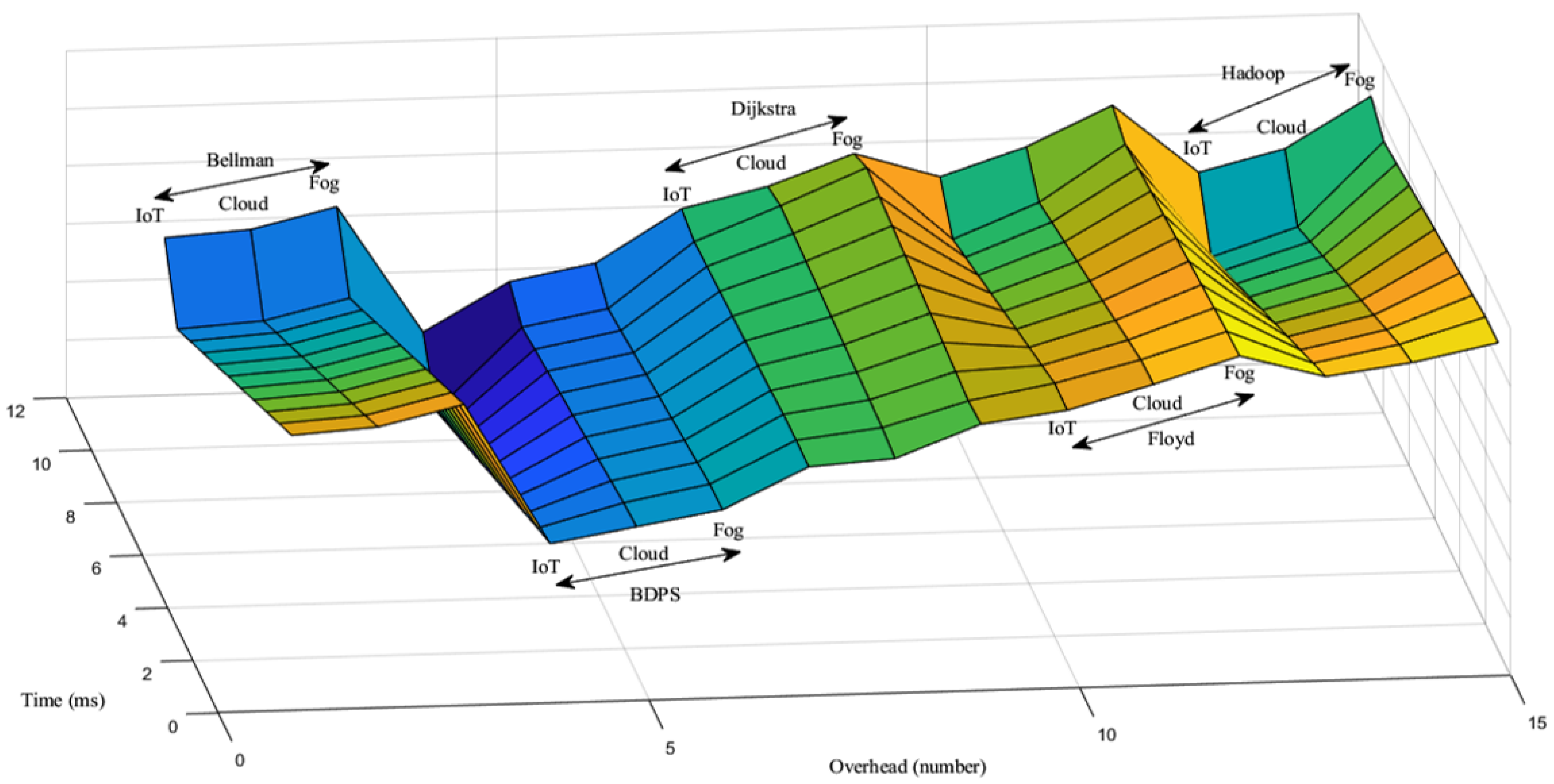
5.2. Network Overhead Generation Scenario over the FW, AH, BF, DA and BDPS Algorithms in Cloud, Fog, and IoT Orchestration
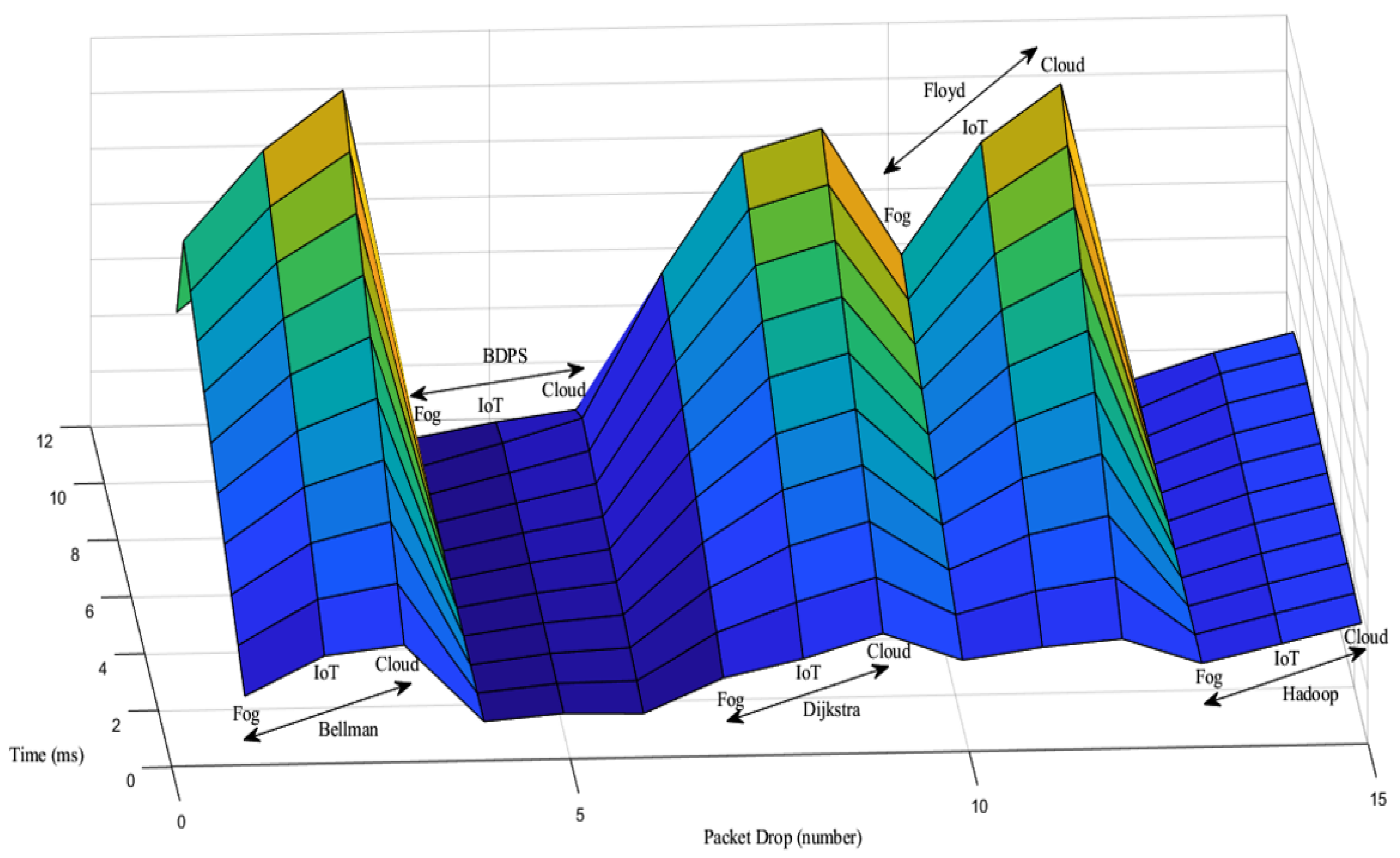
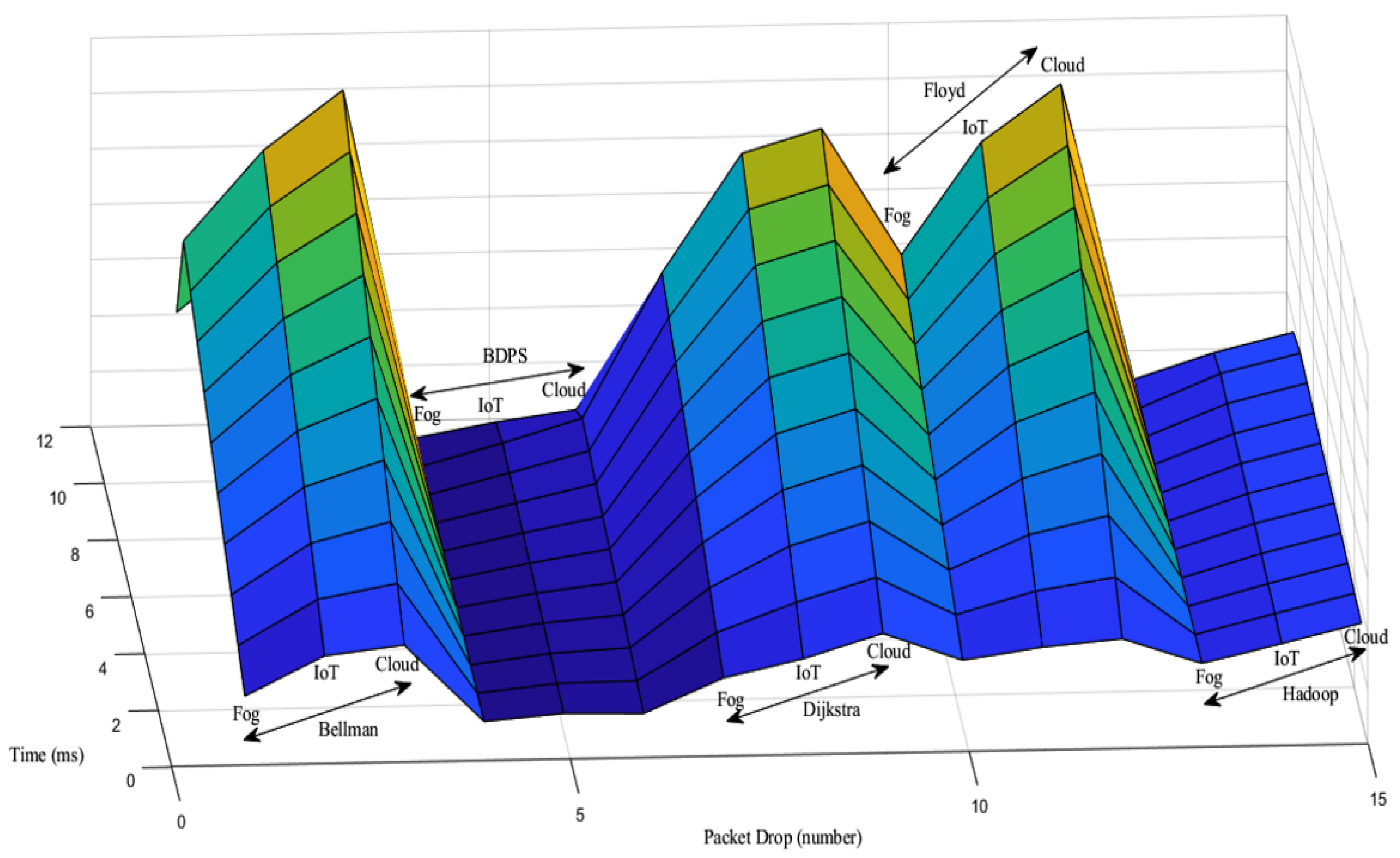
5.3. Packet Drop Generation Scenario over the FW, AH, BF, DA and BDPS Algorithms in Cloud, Fog, and IoT Orchestration
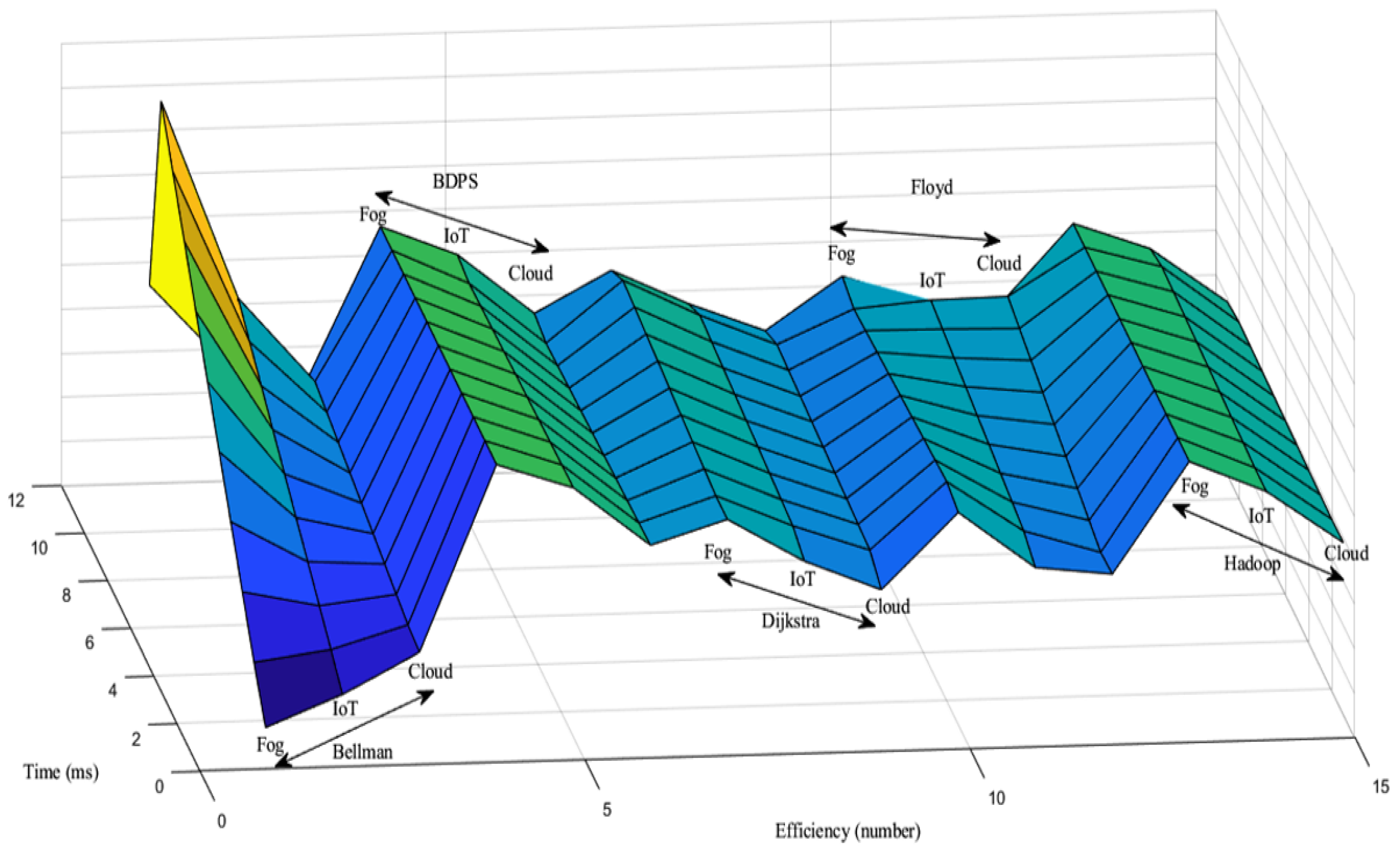
5.4. Network Efficiency Generation Scenario over the FW, AH, BF, DA and BDPS Algorithms in Cloud, Fog, and IoT Orchestration
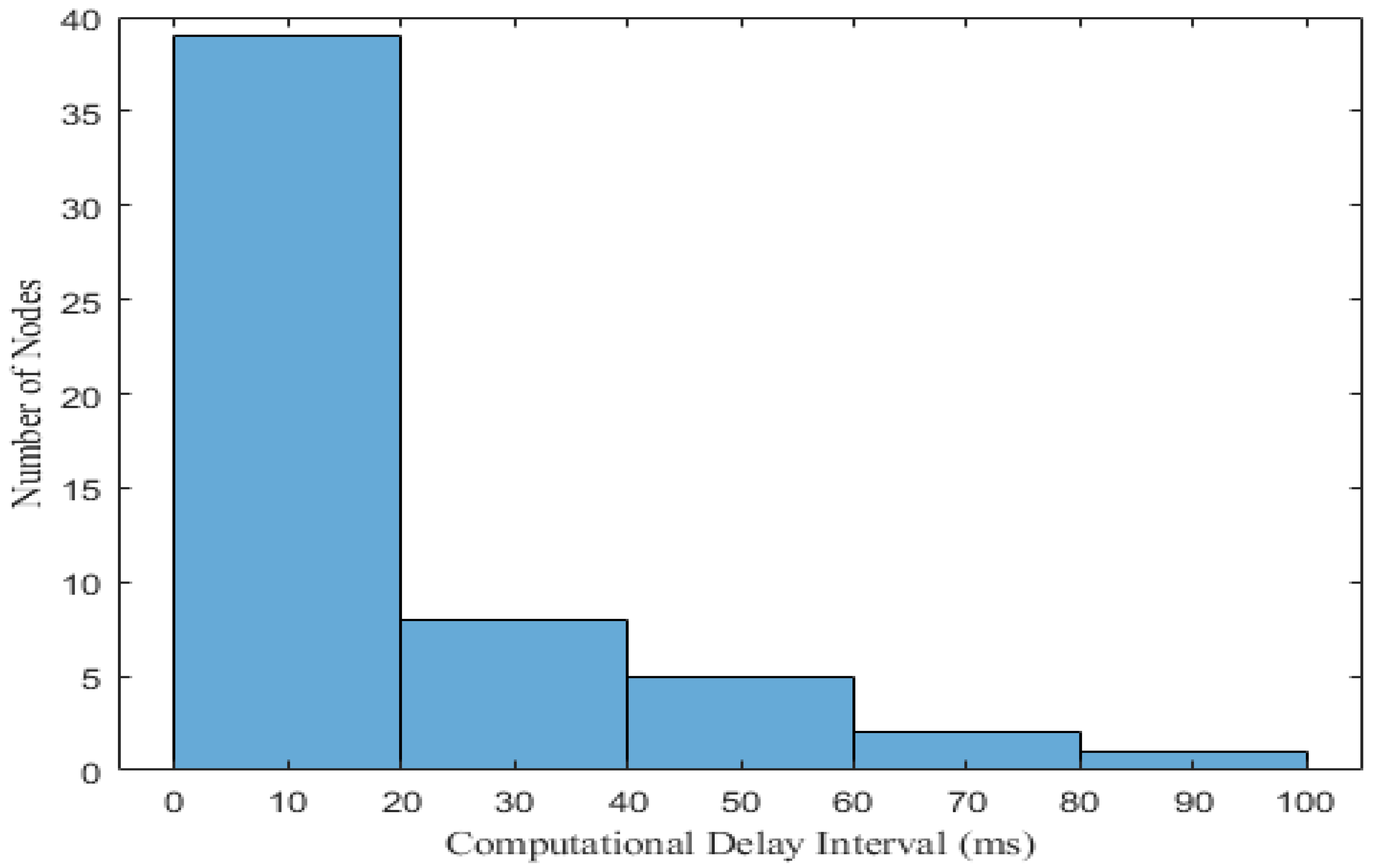
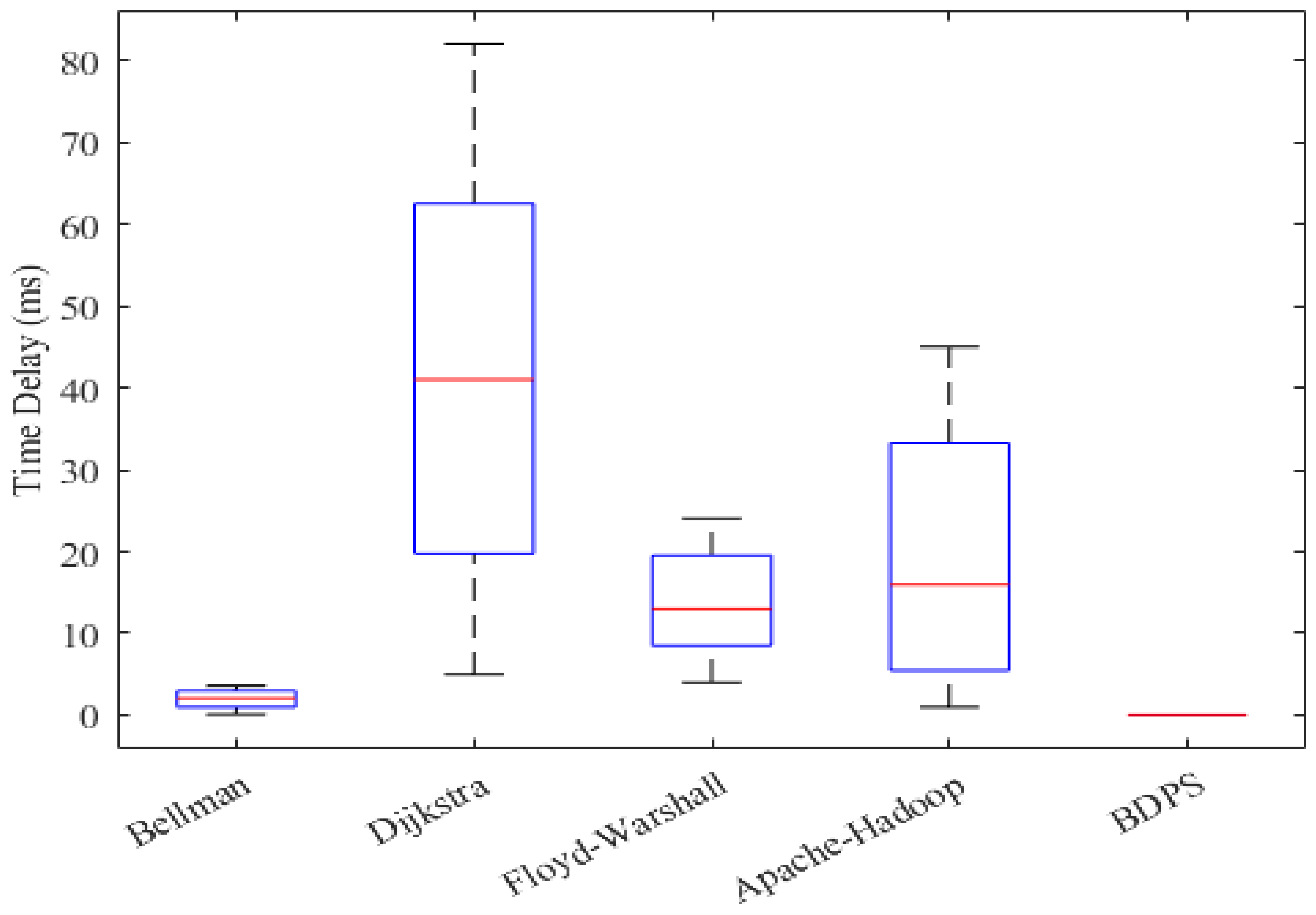
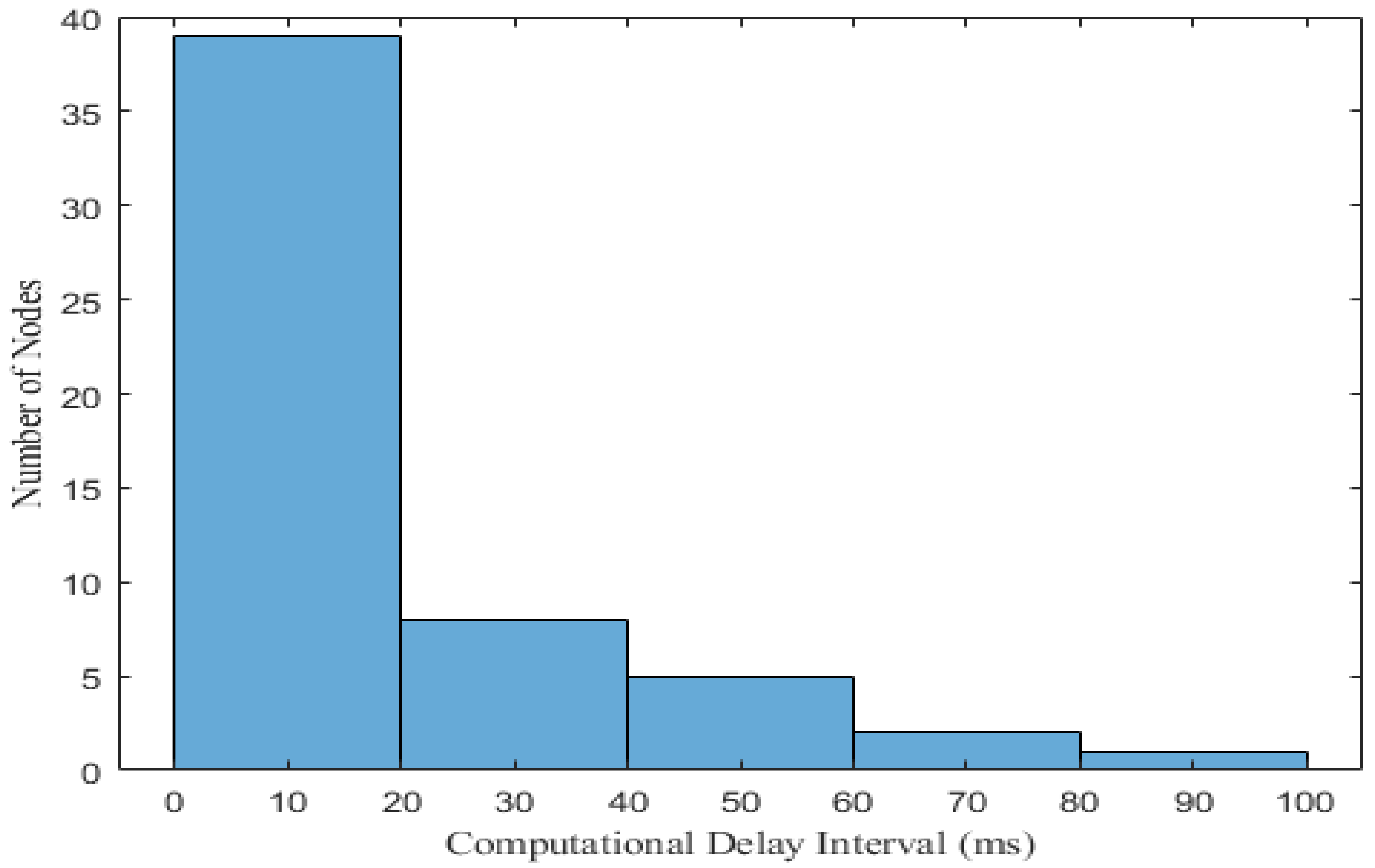
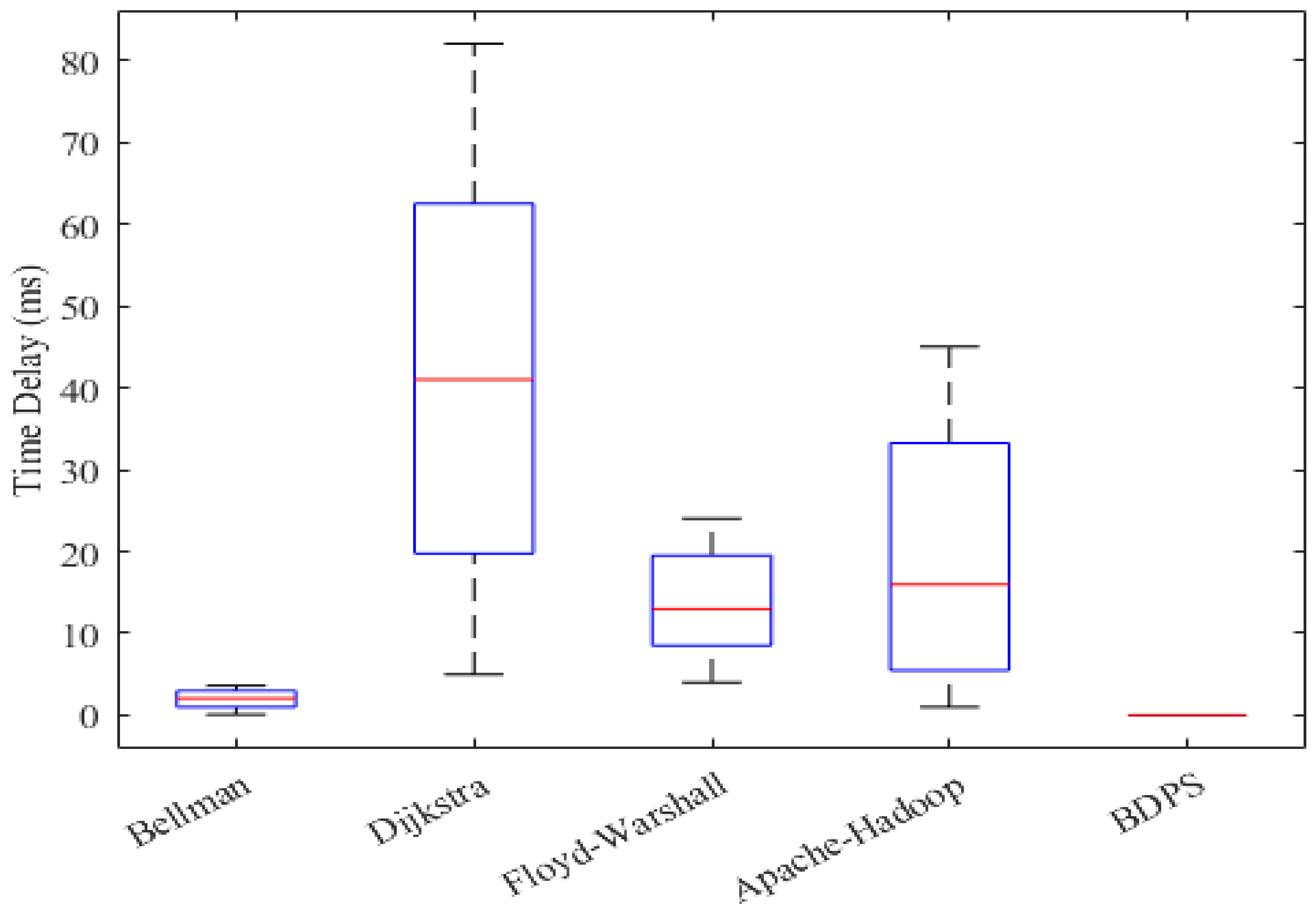
5.5. Computational Delay Generation Scenario over the FW, AH, BF, DA and BDPS Algorithms in Cloud, Fog, and IoT Orchestration
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hossain, M.R.; Whaiduzzaman, M.; Barros, A.; Tuly, S.R.; Mahi, M.J.N.; Roy, S.; Fidge, C.; Buyya, R. A scheduling-based dynamic fog computing framework for augmenting resource utilization. Simul. Model. Pract. Theory 2021, 111, 102336. [Google Scholar] [CrossRef]
- Farjana, N.; Roy, S.; Mahi, M.J.N.; Whaiduzzaman, M. An identity-based encryption scheme for data security in fog computing. In Proceedings of International Joint Conference on Computational Intelligence; Springer: Singapore, 2020; pp. 215–226. [Google Scholar]
- Whaiduzzaman, M.; Gani, A.; Naveed, A. Towards enhancing resource scarce cloudlet performance in mobile cloud computing. Comput. Sci. Inf. Technol. 2015, 5, 1. [Google Scholar]
- Raghavendra, R.; Lobo, J.; Lee, K.W. Dynamic graph query primitives for sdn-based cloudnetwork management. In Proceedings of the First Workshop on Hot Topics in Software Defined Networks, Helsinki, Finland, 13 August 2012; pp. 97–102. [Google Scholar]
- Whaiduzzaman, M.; Naveed, A.; Gani, A. MobiCoRE: Mobile device based cloudlet resource enhancement for optimal task response. IEEE Trans. Serv. Comput. 2016, 11, 144–154. [Google Scholar] [CrossRef]
- Mahi, M.J.N.; Hossain, K.M.; Biswas, M.; Whaiduzzaman, M. SENTRAC: A Novel Real Time Sentiment Analysis Approach Through Twitter Cloud Environment. In Advances in Electrical and Computer Technologies; Springer: Singapore, 2020; pp. 21–23. [Google Scholar]
- EL-Garoui, L.; Pierre, S.; Chamberland, S. A New SDN-Based Routing Protocol for Improving Delay in Smart City Environments. Smart Cities 2020, 3, 1004–1021. [Google Scholar] [CrossRef]
- Firouzi, F.; Farahani, B.; Marinšek, A. The convergence and interplay of edge, fog, and cloud in the AI-driven Internet of Things (IoT). Inf. Syst. 2021, 101840, in press. [Google Scholar] [CrossRef]
- Whaiduzzaman, M.; Mahi, M.J.N.; Barros, A.; Khalil, M.I.; Fidge, C.; Buyya, R. BFIM: Performance Measurement of a Blockchain Based Hierarchical Tree Layered Fog-IoT Microservice Architecture. IEEE Access 2021, 9, 106655–106674. [Google Scholar] [CrossRef]
- Manogaran, G.; Lopez, D.; Chilamkurti, N. In-Mapper combiner based MapReduce algorithm for processing of big climate data. Future Gener. Comput. Syst. 2018, 86, 433–445. [Google Scholar] [CrossRef]
- Ragaventhiran, J.; Kavithadevi, M.K. Map-optimize-reduce: CAN tree assisted FP-growth algorithm for clusters based FP mining on Hadoop. Future Gener. Comput. Syst. 2020, 103, 111–122. [Google Scholar] [CrossRef]
- Whaiduzzaman, M.; Barros, A.; Shovon, A.R.; Hossain, M.R.; Fidge, C. A Resilient Fog-IoT Framework for Seamless Microservice Execution. In Proceedings of the IEEE International Conference on Services Computing (SCC), Chicago, IL, USA, 5–10 September 2021; pp. 213–221. [Google Scholar]
- Awan, M.J.; Farooq, U.; Babar, H.M.A.; Yasin, A.; Nobanee, H.; Hussain, M.; Hakeem, O.; Zain, A.M. Real-time DDoS attack detection system using big data approach. Sustainability 2021, 13, 10743. [Google Scholar] [CrossRef]
- Whaiduzzaman, M.; Farjana, N.; Barros, A.; Mahi, M.; Nayeen, J.; Satu, M.; Roy, S.; Fidge, C. HIBAF: A data security scheme for fog computing. J. High Speed Netw. 2021, 27, 381–402. [Google Scholar] [CrossRef]
- Adoni, W.Y.H.; Nahhal, T.; Aghezzaf, B.; Elbyed, A. The MapReduce-based approach to improve the shortest path computation in large-scale road networks: The case of A* algorithm. J. Big Data 2018, 5, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Quasim, M.T. Resource Management and Task Scheduling for IoT using Mobile Edge Computing. Wirel. Pers. Commun. 2021, 1–18. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, W.; Yang, R.; Guo, M.; Chen, C.M. A distributed computation of the shortest path in large-scale road network. J. Ambient. Intell. Humaniz. Comput. 2019, 1–16. [Google Scholar] [CrossRef]
- Alazzam, H.; AbuAlghanam, O.; Sharieh, A. Best path in mountain environment based on parallel A* algorithm and Apache Spark. J. Supercomput. 2021, 1–20. [Google Scholar] [CrossRef]
- Aslanpour, M.S.; Gill, S.S.; Toosi, A.N. Performance evaluation metrics for cloud, fog and edge computing: A review, taxonomy, benchmarks and standards for future research. Internet Things 2020, 12, 100273. [Google Scholar] [CrossRef]
- Whaiduzzaman, M.; Sookhak, M.; Gani, A.; Buyya, R. A survey on vehicular cloud computing. J. Netw. Comput. Appl. 2014, 40, 325–344. [Google Scholar] [CrossRef]
- Eswaran, S.P.; Sripurushottama, S.; Jain, M. Multi criteria decision making (mcdm) based spectrum moderator for fog-assisted internet of things. Procedia Comput. Sci. 2018, 134, 399–406. [Google Scholar] [CrossRef]
- Moertini, V.S.; Adithia, M.T. Uncovering Active Communities from Directed Graphs on Distributed Spark Frameworks, Case Study: Twitter Data. Big Data Cogn. Comput. 2021, 5, 46. [Google Scholar] [CrossRef]
- Oma, R.; Nakamura, S.; Duolikun, D.; Enokido, T.; Takizawa, M. Fault-tolerant fog computing models in the IoT. In Proceedings of the 13th International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, Taichung, Taiwan, 27–29 October 2018; pp. 14–25. [Google Scholar]
- Abdel-Basset, M.; Mohamed, R.; Elhoseny, M.; Bashir, A.K.; Jolfaei, A.; Kumar, N. Energy-aware marine predators algorithm for task scheduling in IoT-based fog computing applications. IEEE Trans. Ind. Inform. 2020, 17, 5068–5076. [Google Scholar] [CrossRef]
- Huang, W.; Zhou, J.; Zhang, D. On-the-Fly Fusion of Remotely-Sensed Big Data Using an Elastic Computing Paradigm with a Containerized Spark Engine on Kubernetes. Sensors 2021, 21, 2971. [Google Scholar] [CrossRef]
- Whaiduzzaman, M.; Ismail Sumi, A.; Barros, A.; Satu, M.S.; Razon Hossain, M. Towards Latency Aware Emerging Technology for Internet of Vehicles. In Proceedings of the 25th Pacific Asia Conference on Information Systems (PACIS), Dubai, United Arab Emirates, 12–14 July 2021. [Google Scholar]
- Tajalli, S.Z.; Mardaneh, M.; Taherian-Fard, E.; Izadian, A.; Kavousi-Fard, A.; Dabbaghjamanesh, M.; Niknam, T. DoS-resilient distributed optimal scheduling in a fog supporting IIoT-based smart microgrid. IEEE Trans. Ind. Appl. 2020, 56, 2968–2977. [Google Scholar] [CrossRef]
- Forti, S.; Gaglianese, M.; Brogi, A. Lightweight self-organising distributed monitoring of Fog infrastructures. Future Gener. Comput. Syst. 2021, 114, 605–618. [Google Scholar] [CrossRef]
- Lu, Z.; Wang, N.; Wu, J.; Qiu, M. IoTDeM: An IoT Big Data-oriented MapReduce performance prediction extended model in multiple edge clouds. J. Parallel Distrib. Comput. 2018, 118, 316–327. [Google Scholar] [CrossRef]
- Swain, C.; Sahoo, M.N.; Satpathy, A.; Muhammad, K.; Bakshi, S.; Rodrigues, J.J.; de Albuquerque, V.H.C. METO: Matching Theory Based Efficient Task Offloading in IoT-Fog Interconnection Networks. IEEE Internet Things J. 2021, 8, 12705–12715. [Google Scholar] [CrossRef]
- Saito, T.; Nakamura, S.; Enokido, T.; Takizawa, M. August. Topic-based processing protocol in a mobile fog computing model. In Proceedings of the 23rd International Conference on Network-Based Information Systems (NBiS-2020), Victoria, BC, Canada, 31 August–2 September 2020; pp. 43–53. [Google Scholar]
- Vijayalakshmi, R.; Vasudevan, V.; Kadry, S.; Lakshmana Kumar, R. Optimization of makespan and resource utilization in the fog computing environment through task scheduling algorithm. Int. J. Wavelets Multiresolut. Inf. Process. 2020, 18, 1941025. [Google Scholar] [CrossRef]
- Ortiz, G.; Zouai, M.; Kazar, O.; Garcia-de-Prado, A.; Boubeta-Puig, J. Atmosphere: Context and situational-aware collaborative IoT architecture for edge-fog-cloud computing. Comput. Stand. Interfaces 2022, 79, 103550. [Google Scholar] [CrossRef]
- Postoaca, A.V.; Negru, C.; Pop, F. Deadline-aware Scheduling in Cloud-Fog-Edge Systems. In Proceedings of the IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), Melbourne, Australia, 11–14 May 2020; pp. 691–698. [Google Scholar]
- Moura, J.; Hutchison, D. Fog computing systems: State of the art, research issues and future trends, with a focus on resilience. J. Netw. Comput. Appl. 2020, 169, 102784. [Google Scholar] [CrossRef]
- Yassine, A.; Singh, S.; Hossain, M.S.; Muhammad, G. IoT big data analytics for smart homes with fog and cloud computing. Future Gener. Comput. Syst. 2019, 91, 563–573. [Google Scholar] [CrossRef]
- Saba, U.K.; ul Islam, S.; Ijaz, H.; Rodrigues, J.J.; Gani, A.; Munir, K. Planning Fog networks for time-critical IoT requests. Comput. Commun. 2021, 172, 75–83. [Google Scholar] [CrossRef]
- Li, L.; Guo, M.; Ma, L.; Mao, H.; Guan, Q. Online workload allocation via fog-fog-cloud cooperation to reduce IoT task service delay. Sensors 2019, 19, 3830. [Google Scholar] [CrossRef] [Green Version]
- Baranwal, G.; Vidyarthi, D.P. FONS: A fog orchestrator node selection model to improve application placement in fog computing. J. Supercomput. 2021, 77, 10562–10589. [Google Scholar] [CrossRef]
- Honar Pajooh, H.; Rashid, M.A.; Alam, F.; Demidenko, S. IoT Big Data provenance scheme using blockchain on Hadoop ecosystem. J. Big Data 2021, 8, 1–26. [Google Scholar] [CrossRef]
- Bendechache, M.; Svorobej, S.; Takako Endo, P.; Lynn, T. Simulating resource management across the cloud-to-thing continuum: A survey and future directions. Future Internet 2020, 12, 95. [Google Scholar] [CrossRef]
- Markakis, E.K.; Karras, K.; Sideris, A.; Alexiou, G.; Pallis, E. Computing, caching, and communication at the edge: The cornerstone for building a versatile 5G ecosystem. IEEE Commun. Mag. 2017, 55, 152–157. [Google Scholar] [CrossRef]
- Wang, J.; Li, D. Task scheduling based on a hybrid heuristic algorithm for smart production line with fog computing. Sensors 2019, 19, 1023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Niu, X.; Shao, S.; Xin, C.; Zhou, J.; Guo, S.; Chen, X.; Qi, F. Workload allocation mechanism for minimum service delay in edge computing-based power Internet of Things. IEEE Access 2019, 7, 83771–83784. [Google Scholar] [CrossRef]
- Ali, B.; Pasha, M.A.; ul Islam, S.; Song, H.; Buyya, R. A Volunteer-Supported Fog Computing Environment for Delay-Sensitive IoT Applications. IEEE Internet Things J. 2020, 8, 3822–3830. [Google Scholar] [CrossRef]
- Losada, M.; Cortés, A.; Irizar, A.; Cejudo, J.; Pérez, A. A Flexible Fog Computing Design for Low-Power Consumption and Low Latency Applications. Electronics 2021, 10, 57. [Google Scholar] [CrossRef]
- Taherizadeh, S.; Apostolou, D.; Verginadis, Y.; Grobelnik, M.; Mentzas, G. A Semantic Model for Interchangeable Microservices in Cloud Continuum Computing. Information 2021, 12, 40. [Google Scholar] [CrossRef]
- Rocha Neto, A.; Silva, T.P.; Batista, T.; Delicato, F.C.; Pires, P.F.; Lopes, F. Leveraging edge intelligence for video analytics in smart city applications. Information 2021, 12, 14. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| APSP | ALL pair shortest path |
| AH | Apache Hadoop algorithm |
| BF | Bellman–Ford algorithm |
| DA | Dijkstra algorithm |
| DFS | Depth-first search algorithm |
| FW | Floyd–Warshall algorithm |
| IoT | Internet of Things |
| BDPS | Spark-RDD-in-memory-based scheme |
| RAMA | Read-only memory accelerator |
| RDD | Resilient data distributor |
| SP | Session password |
| Works | Key Technologies | Contributions and Research Gap | ||||
|---|---|---|---|---|---|---|
| Cloud | Fog | IoT | Map.R | Big.D | ||
| Farjana et al. (2020) [2] | ✓ | ✓ | ✓ | X | X | Security issues declared in fog only services. |
| Ramya et al. (2012) [4] | ✓ | X | X | X | X | Dynamic graph query module for NaaS Cloud. |
| Oma et al. (2018) [23] | X | X | ✓ | X | X | WSN platform for serving lower fogs. |
| Tajalli et al. (2020) [27] | X | X | ✓ | X | X | DoS security aware framework for WSANs. |
| Forti et al. (2021) [28] | X | X | X | ✓ | X | Application placement for map reduced services. |
| Zhihui et al. (2017) [29] | X | X | ✓ | ✓ | ✓ | Weighted Linear Regression for hadoop clusters. |
| Swain et al. (2020) [30] | X | ✓ | ✓ | X | X | TDMA task offload scheduler for fog-IoT nodes. |
| Saito et al. (2020) [31] | X | X | ✓ | X | X | Wireless message subscription model for IoT nodes. |
| Vasudevan et al. (2020) [32] | X | X | ✓ | X | X | Scheduler problem in distributed IoT labeling. |
| Ortiz et al. (2022) [33] | ✓ | ✓ | ✓ | X | X | Inappropriate 3-tier interfacing for large data set. |
| Postoaca et al. (2020) [34] | ✓ | X | X | X | X | Distributed algorithmic access for cloud datacenter. |
| Yassine et al. (2018) [36] | ✓ | ✓ | ✓ | X | ✓ | Only big data based task schedulers. |
| Saba et al. (2021) [37] | X | ✓ | ✓ | X | X | Dynamic IoT traffic model for fog analytics. |
| Li et al. (2019) [38] | ✓ | ✓ | ✓ | X | X | Shortest paths algorithms for road networks. |
| Baranwal et al. (2021) [39] | ✓ | ✓ | ✓ | X | X | Data deliverable services and shared architectures. |
| Honar et al. (2021) [40] | ✓ | X | ✓ | X | ✓ | Facing trouble in middle ware latency support. |
| Bendechache et al. (2020) [41] | ✓ | ✓ | ✓ | X | X | Gap in middleware feasibilities. |
| Losada et al. (2021) [46] | ✓ | ✓ | ✓ | X | X | Gaps in between Proposed and ES scheme. |
| Symbol | Definition |
|---|---|
| Current process packet | |
| Increment of packet stacks to the next upcoming | |
| Cloud session service container | |
| Fog mapreduce-Spark service container | |
| IoT cluster session service | |
| n | Processing packet at first start |
| Performance Criterion | Baselines |
|---|---|
| Throughput [Mb/s] | Cloud Orchestrated Fog-IoT network |
| Node Failure Rate [%] | Spark-RDD based Fog-IoT Controller Scheduling |
| Computational Delay [s] | Schedule-Aware Bundle Routing (SABR) |
| Bandwidth Prediction [Kb/s] | Preemptive Scheduling Regressor |
| Spark-RDD Regressor | |
| Asymptotic Regressor |
| Simulation Parameters | Values |
|---|---|
| Software Centric Parameters | |
| Network emulator | OMNET++ 5.5.3; Jupyter Notebook 6.1.0; |
| ns-3.2.1; iFogSim | |
| Cloud storage platform | Owncloud 10.3 |
| Packet analyzer | Wireshark Packet Analyzer |
| Programming language | Python 3.5.3, Java 9, C++17 |
| Simulation Parameters | Values |
|---|---|
| Cloud Parameters | |
| No. of Fog controllers | 1 |
| No. of CloudBus switches | 2 |
| No. of Cloud gateways | 1 |
| Type of Cloud controllers | HP Z4 G4 Workstation |
| Cloud routing protocol | TCP/IP |
| Fog Parameters | |
| No. of Fog controllers | 4 |
| No. of FogBus switches | 6 |
| No. of Fog gateways | 4 |
| Type of Fog controllers | Dell Optiplex 3060 MT; Raspberry Pi 3b+ |
| Fog routing protocol | TCP/IP |
| IoT Parameters | |
| Mobility model | Reference point group model (RPGM) |
| Type of IoT Controller | Amazon Fire HD 7; Dell Edge Gateway 5000 |
| Traffic type | Constant Bit Rate (CBR) |
| Number of IoT devices | 100 |
| Simulation time | 600 s |
| Simulation area | 5000 m × 5000 m |
| Data rate | 20 Mbps |
| Transmitted packet size | 256–1024 B |
| Initial energy value | 10–12 J |
| Initial trust value | 5 J |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossen, R.; Whaiduzzaman, M.; Uddin, M.N.; Islam, M.J.; Faruqui, N.; Barros, A.; Sookhak, M.; Mahi, M.J.N. BDPS: An Efficient Spark-Based Big Data Processing Scheme for Cloud Fog-IoT Orchestration. Information 2021, 12, 517. https://doi.org/10.3390/info12120517
Hossen R, Whaiduzzaman M, Uddin MN, Islam MJ, Faruqui N, Barros A, Sookhak M, Mahi MJN. BDPS: An Efficient Spark-Based Big Data Processing Scheme for Cloud Fog-IoT Orchestration. Information. 2021; 12(12):517. https://doi.org/10.3390/info12120517
Chicago/Turabian StyleHossen, Rakib, Md Whaiduzzaman, Mohammed Nasir Uddin, Md. Jahidul Islam, Nuruzzaman Faruqui, Alistair Barros, Mehdi Sookhak, and Md. Julkar Nayeen Mahi. 2021. "BDPS: An Efficient Spark-Based Big Data Processing Scheme for Cloud Fog-IoT Orchestration" Information 12, no. 12: 517. https://doi.org/10.3390/info12120517
APA StyleHossen, R., Whaiduzzaman, M., Uddin, M. N., Islam, M. J., Faruqui, N., Barros, A., Sookhak, M., & Mahi, M. J. N. (2021). BDPS: An Efficient Spark-Based Big Data Processing Scheme for Cloud Fog-IoT Orchestration. Information, 12(12), 517. https://doi.org/10.3390/info12120517